(AI501) 8. Unconstrained optimization
본 포스팅은 AI501 수업에서 제가 새로 알게 된 부분만 정리한 것입니다.
Optimization
- loss 함수를 최소로 만드는 parameter $\theta$를 찾는 것
- least square loss, maximum likelihood
Gradient descent
- step size control
- Cosine annealing, hyperparameter tuning, line search
- moderate value에서 점차적으로 줄이는 것
- Gradient descent with momentum
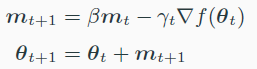
- Nesterov’s accelerated gradient
- Empirical loss가 n이 $\inf$로 갈 때, true loss가 된다.
- Stochastic gradient descent
- AdaGrad
- loss function의 미분의 크기에 반비례해서 update함.
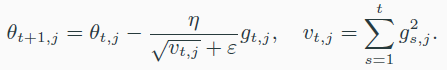
- RMSProp
- ada grad랑 비슷하다.
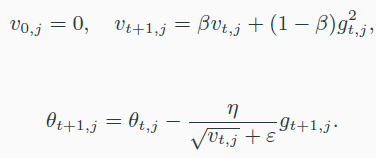
- Adam
- RMSProp + momentum
- 결론
- adam : tuning 많이 안해도 moderate한 결과
- sgd + momentum + heavy tuning : best 결과