(AI502) 5. regularization
본 포스팅은 AI502수업에서 제가 새로 알게 된 부분만 정리한 것입니다.
Regularization
Regularization 방법
- constraints를 추가
- parameter value에 restriction을 주기
- learning object에 extra term을 두어 param value에 soft constraint를 주는 것.
- multiple hyphtheses를 합치는 것
- numerical optimization process를 수정
- data augumentation
Bias, Variance
$Bias[h(x)] = \bar{h(x)}-f(x)$
$Var[h(x)] = E[(h(x)-\bar{h(x)})^2]$
$Noise[h(x)] = E[(y-f(x))^2] = E[\epsilon^2] = \sigma^2$
$E[(y-h(x))^2] = Variance + Bias^2 + Noise$
Simple model $\Rightarrow$ high bias, low variance
Complex model $\Rightarrow$ low bias, high variance
대부분의 Regularization method는 variance를 줄이고, bias를 추가한다.
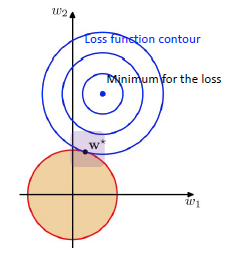
Norm-based Regularization
- L2 Regularizer
 s
s- weight의 크기를 제한
- Ridge regression
- ‘각 계수의 제곱을 더한 값’을 식에 포함하여 계수의 크기도 함께 최소화하도록 만들었다.
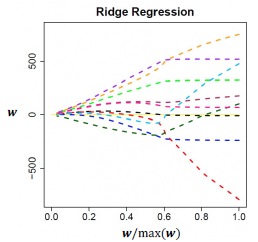
- w1, … , wn이 동시에 0로 수렴한다.
- Weight decay
- L2에 대한 고찰
- object function을 taylor expansion을 이용하여 전개하고 그것을 미분하면, 결국 아래와 같은 결과가 나온다.
- weight decay는 H의 eigenvector을 따라 w*를 $\frac{\lambda_{i}}{\lambda_{i}+\alpha}$로 rescales
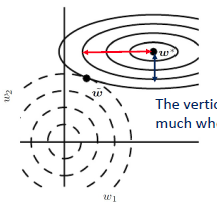
- L1 Regularizer
- parameter selection
- Lasso (L1-regularized Linear Regression)
- 모든 variable이 동시에 zero가 되지 않아서 variable selection을 하게 된다.
- 미분 불가능할때(L1 norm과 같이) gradient 구하는법
- Subgradient Method
- L1 norm은 non-smooth하기 때문에 set of gradients를 구한다.
- Proximal Gradient
- Subgradient Method
- L0-psuedonorm
- non-zero variable의 개수
- learning sparse models by selecting variables
- feature selection, model compression, better interpretability
- Lp norm
- p가 2보다 작으면 sparsity(몇몇 informative feature를 선택)
- p가 2보다 크면 grouping(correlated한 feature를 비슷한 weight로 만듦)
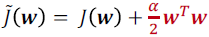
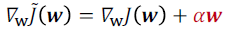
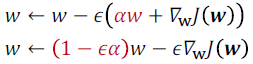


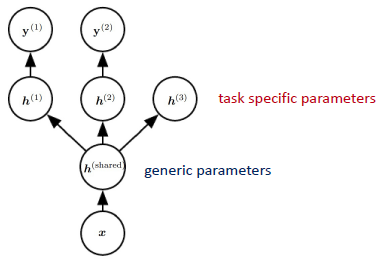
Multi-task Learning, Ensemble Methods, and Bagging
- Multi-task Learning
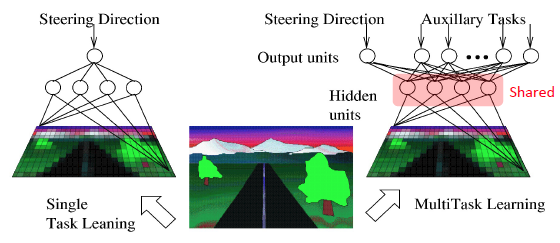
- generalize하는데 도움 됌.
- 2 부분으로 나눠질 수 있다.
- Ensemble
- combine by consensus : bagging, random forest, model averaging
- 결과를 majority voting이나 averaging한다.
- 장점 : label 필요없음, generalization 성능 높임
- 단점 : label로 부터 피드백, model bias도 최소화함
- combine by learning : boosting, rule ensemble, bayesian model averaging
- model을 하나로 합친다. (dropout)
- 장점 : label로 부터 피드백이 없음, consensus를 믿고함
- 단점 : labeled data가 필요, overfit, 라벨이 필요
- combine by consensus : bagging, random forest, model averaging