Inductive bias
논문에서 Vision transformer은 CNN보다 less inductive bias가 적다고 나옴. inductive bias의 정의는 아래와 같다.
학습 모델이 지금까지 만나보지 못했던 상황에서 정확한 예측을 하기 위해 사용하는 추가적인 가정을 의미
Inductive bias를 사용하는 이유 : brittle / spurious
- model이 brittle하다.
- input이 조금만 바뀌어도 결과가 망가지는 것
- model이 spurious하다
- 데이터 본연의 의미를 학습하는 것이 아닌 결과(artifacts)와 편향(biases)를 학습하는 것. 배경에 바다가 있으면 갈매기로 학습하는 것.
위와 같이 model이 brittle 하거나 spurious 하게 되는 것을 막기 위해 Inductive bias 를 사용
Inductive bias의 예시
- Translation invariance : 사물의 위치가 바뀌어도 인식
- Translation Equivariance : 사물의 위치가 바뀌면 CNN과 같은 연산의 activation 위치가 바뀜
- Maximum conditional independence : 가설이 베이지안 프레임 워크에 캐스팅 될 수 있다면 조건부 독립성을 극대화함 (바다가 있으면 갈매기라고 인식하는 것이 아니라 바다와 갈매기를 분리)
- Minimum cross-validation error : 가설 중에서 선택하려고 할 때 교차 검증 오차가 가장 낮은 가설을 선택합니다. (valid error가 낮은 모델을 선택한다)
- Maximum margin : 두 클래스 사이에 경계를 그릴 때 경계 너비를 최대화합니다.
- Minimum description length : 가설을 구성할 때 가설의 설명 길이를 최소화합니다. 이는 더 간단한 가설은 더 사실일 가능성이 높다는 가정을 기반으로 하고 있습니다.
- Minimum features: 특정 피쳐가 유용하다는 근거가 없는 한 삭제해야 합니다.
- Nearest neighbors: 특징 공간에 있는 작은 이웃의 경우 대부분이 동일한 클래스에 속한다고 가정합니다.
딥러닝에서 Inductive bias
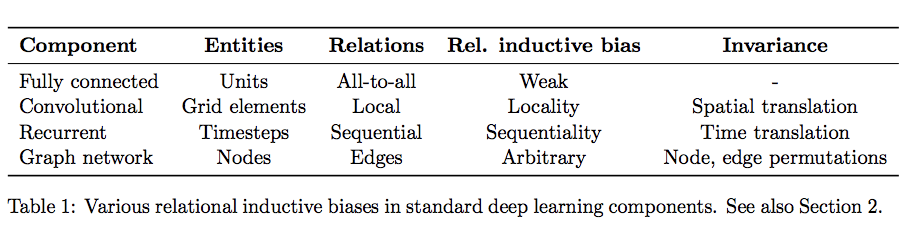
딥러닝에서 레이어는 Relational Inductive bias와 hierarchical process를 제공한다.
아래 표와 같이 FC layer는 weak, conv layer는 locality, Reccuent layer는 Sequentially, GNN 은 Arbitrary하다. (이 부분은 아직 이해하지 못했다.)
Inductive bias의 효과
Inductive bias가 강하면 sample efficiency가 좋아진다. (few shot learning이 가능하다는 뜻?) 하지만 가정이 강하게 들어간 만큼 좋게 볼 수는 없다.
따라서 현대의 딥러닝은 가정을 덜 쓰는 “End-to-End”로 설계를 한다.
하지만 몇몇 딥러닝 아키텍처(GNN)은 더 강한 Inductive Bias를 만드는 것에 관련되어 있다.
—
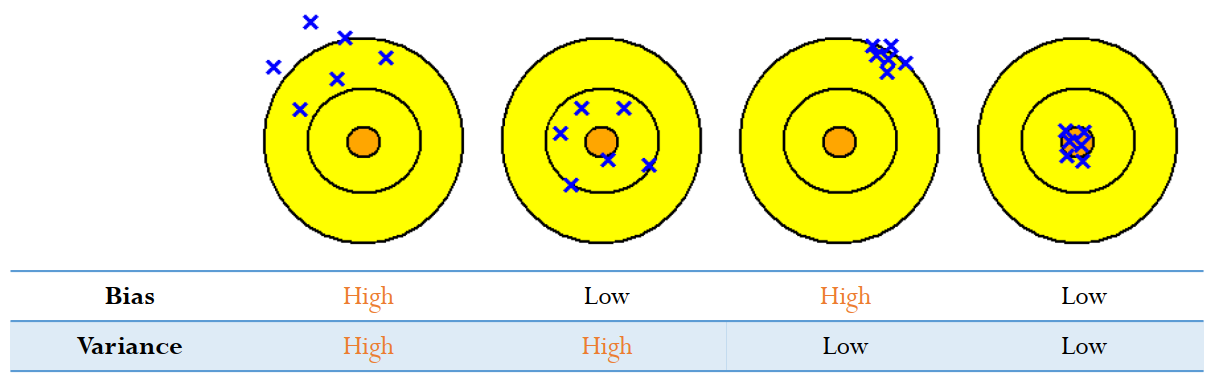
Bias 와 Variance
추가적으로 error를 구성하는 bias와 variance는 아래와 같은 의미를 가진다. 이 둘을 trade-off 관계를 가진다.
Bias는 아래 그림과 같이 예측값들의 평균의 오차 Variance는 예측값들이 퍼져있는 정도
출처
본 포스팅은 아래 사이트들을 참고하여 작성되었습니다.