본 포스팅은 아래 논문을 참고했습니다. https://arxiv.org/pdf/1706.03762.pdf
Transformer
1. Introduction
RNN, LSTM, gated RNN 등 Recurrent model 등은 position을 정렬해서 학습하는 방법이다. 이런 방법들은 sequence의 길이가 길 때 취약하다는 문제가 있었다. 이 문제를 해결하기 위해 factorization trick, conditional computation 등의 최근의 시도가 있었다. 하지만 sequential computation이 가지는 한계는 여전했다.
본 논문에서는 이런 문제를 해결하기 위해 Transformer라는 구조를 제안했다. 이는 Recurrene는 없애고, input과 output의 global dependency를 이끌기 위해 attention mechanism에 전적으로 의존하는 구조이다.
2. Background
- 연속적인 계산을 줄이기 위해 Extended Neural GPU, ByteNet, ConvS2S 등이 나왔다. 이것은 input과 output에 hidden representation을 parallel하게 계산했다. 이것은 distant position의 의존도를 학습하기 어려웠다.
- Self-attention(intra-attention) : single sequence의 다른 position과 관련된 attention machanism, single sequence에서 representation을 얻는 방법.
- Transformer는 RNN과 CNN을 사용하지 않고, self-attention만을 이용하는 첫 transduction model
3. Model Architecture
sequence transduction model은 encoder-decoder 구조로 되어있다. Encoder의 마지막 레이어의 출력이 Decoder의 multi-head attention으로 들어간다. Encoder 쪽에는 Q, K, V가 모두 같은 self-attention 이 있고, Decoder 쪽에는 masked한 self-attention과 multi-head attention이 있다.
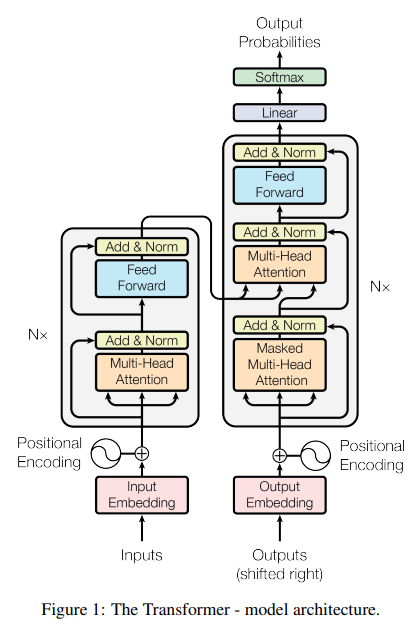
3.1 encoder-decoder 구조
- stacked self-attention
- point-wise, fc layer 사용
3.1.1 Encoder
- 6 layers
- 2 sub layer
- multi-head self-attention
- simple, position-wise fully connected feed-forward network
- 각 sub layer 뒤에 residual connection, layer normalization
- 모든 sub layer의 output과 embedding layer의 output은 d_model(512)으로 맞춤
3.1.2 Decoder
- 6 layers
- 3 sub layer
- multi-head attetion 2개
- feed-forward network 1개
- 각 sub layer 뒤에 residual connection, layer normalization
- 모든 sub layer의 output과 embedding layer의 output은 d_model(512)으로 맞춤
- masking : This masking, combined with fact that the output embeddings are offset by one position, ensures that the predictions for position i can depend only on the known outputs at positions less than i (이해 못함)
3.2.1 Scaled Dot-Product Attention
흔히 사용되는 attension function은 2 종류 (additive attention, dot-product attention)
논문에서는 additive attention에서 scaling factor를 추가해서 사용
$scaling factor=\frac{1}{\sqrt{d_k}}$ dot-product attetion : faster, more space-efficient
additive attention : d_k가 크면 성능 좋음
$Attension(Q, K, V)=softmax(\frac{QK^T}{\sqrt{d_k}})V$
3.2.2 Multi-Head Attention

3.2.3 Multi-Head Attention을 쓰는 3가지 방법
- encoder-decoder attention : 이전 decoder에서 query를 얻고, encoder에서 key와 value를 얻는다. 하나의 query를 각 key와 value에 적용한다.
- encoder contains self-attention layers : 이전 encoder에서 나온 keys, values, queries 가 다음 encoder로 들어간다.
- self-attention layers in the decoder : 뒤쪽 단어를 masked 해서 사용한다.
3.3 Position-wise Feed-forward networks
Transformer에 들어가는 feed-forward network는 2개의 layer로 구성되어 있다. input과 output의 차원은 d_model(512)이고, inner-layer는 d_ff(2048)이다. conv 필터는 커널 사이즈가 1이다.
3.4 Embeddings and softmax
- input token과 output token을 d_model 차원의 벡터로 변환하기 위해 embedding을 학습하여 사용
- 또한 decoder의 출력으로부터 다음 token의 확률을 예측하기 위해 linear transformation를 사용한다.
- 2 embedding layer와 linear transformation 은 같은 weight를 공유하고, 그 weight에 $\sqrt{d_{model}}$을 곱한다.
3.5 Positional Encoding
이 논문에서는 sine, cosine 함수로 사용했다. position embedding을 학습해서 해도 비슷한 결과가 나왔다. 그럼에도 sinusoid를 사용한 것은 learned position embedding 할 때 모델이 train에 사용한 sequence의 길이보다 더 긴 순서 길이를 사용할 수 있기 때문이다.
4. Self-attention
self-attention의 장점은 3가지가 있다.
- computational complexity
- parallel한 computation
- path length
- (+ interpretable model)

-
대부분의 상황에서 sequence의 길이 n은 representation dimension d보다 작다. 따라서 위 표에서 RNN과 CNN을 비교했을 때, transformer의 Computation Complexity가 낮다는 것을 알 수 있다.
-
길이에 상관없이 operation이 O(1)이다.
5. Train
5.1 Training 방법
- WMT 2014 English-German, English-French data로 학습했다.
- 8개의 P100으로 100000 step, 12 시간 학습했다.
- Adam optimizer로 beta1은 0.9, beta2는 0.98, $\epsilon$은 $10^{-9}$, warmup step을 두고 step이 지날때마다 비례해서 줄였다.
- Residual dropout : ?
- Label smoothing : $\epsilon_{ls}$ 는 0.1, 이것은 perplexity에 손실을 주지만, BLEU를 향상시킵니다.
PPL, BLEU, Label smoothing
- PPL : 문장의 길이로 정규화한 문장 확률의 역수. 낮을수록 언어 모델의 성능이 좋다는 것을 의미한다는 점입니다. <br>
- BLEU : 기계 번역 결과와 사람이 직접 번역한 결과가 얼마나 유사한지 비교하여 번역에 대한 성능을 측정하는 방법 <br>
- Label smoothing : 라벨을 깎아서 모델을 Regularize하는 것.
6. Result
6.2 Model Variations
여러 hyper-parameter의 영향력을 알아보기 위해 아래와 같은 테스트를 해봤다.
(A) h의 개수를 바꿔가면서 테스트해봄, h가 16 일때 좋다.
(B) $d_k$를 바꿔가며 테스트, $d_k$를 낮춰서 capacity를 낮추니 성능이 안좋아짐.
(C) capacity를 높이는 방향으로 했을 때 성능이 좋아짐.
(D) dropout을 사용했을 때 성능이 좋아짐.
(E) embedding layer를 추가해서 positional embedding을 했을 때, 성능 변화가 크게 없음
6.3 English Constituency Parsing
구문분석 Task에도 좋은 성능을 보였다.
7. Conclusion
translation task에서 학습이 빨리 됐고, 성능도 좋았다.