Transformer-TTS
본 포스팅은 아래 논문을 참고했습니다.
- https://arxiv.org/pdf/1809.08895.pdf
- https://m.blog.naver.com/PostView.naver?isHttpsRedirect=true&blogId=sooftware&logNo=221661644808
Abstract
- 기존의 end-to-end TTS 방법(Tacotron2)은 두가지 문제가 있었다.
- 학습과 추론 시 낮은 효율성
- RNN으로는 long dependency를 modeling 하기 어려움
- transformer
- multi-head self-attention으로 hidden state가 parallel해졌고, 학습 효율성을 향상시켰다.
- self-attention : long range dependency 문제를 해소
- phoneme음소 시퀀스를 넣으면 WaveNet vocoder로부터 나오는 mel spectrogram으로 출력
- 효율성과 성능을 중심으로 테스트 하였다.
- Tacotron2보다 4.25배 학습 속도가 빨랐다.
-
Tacotron2보다 성능도 좋았다.
MFCC, Mel-Spectrogram
- ‘음성데이터’를 ‘특징벡터’ (Feature) 화 해주는 알고리즘
- MFCC Feature는 파이썬에서는 제공되는 librosa라는 라이브러리를 이용해서 간단하게 뽑아올 수 있다.
- Mel-scale : 사람의 달팽이관 특성 고려, 저주파 대역은 잘 감지, 고주파 대역은 감지 어려움
- 아래와 같이 사용

1. Introduction
TTS의 흐름
- Traditional TTS system은 front-end와 back-end가 있었다.
- front-end는 text 분석, 언어적 특징 추출
- back-end는 음성 합성
- 이런 방법은 복잡하고, 시간도 많이 걸렸고, 성능도 좋지 않았다.
- end-to-end generative tts model
- Tacotron, Tacotron2
- mel spectogram을 text로 부터 추출
- vocoder로 음성 생성(Griffin Lim algorithm, WaveNet)
- encoder랑 decoder로 구성
- encoder : semantic space에 input sequence를 mapping, generate sequence
- decoder : contest information을 받아서 mel frames를 출력
- RNN은 sequentially 하게 동작하기 때문에 예전의 많은 step이 biased 된다.
- Transformer로 long distance dependency 문제를 해소
- ★ Transformer TTS는 mel spectrogram을 합성하고, wavenet을 vocoder로 audio를 합성한다.
2. Background
2.1 Sequence to sequence model
- NMT에서는 vocab 안에 있는 모든 word의 probability를 계싼
- TTS에서는 softmax는 안쓰고, decoder에 의해 계산되는 hidden state가 spectrogram frame을 얻기위해 바로 linear projection에서 사용된다.
2.2 Tacotron2
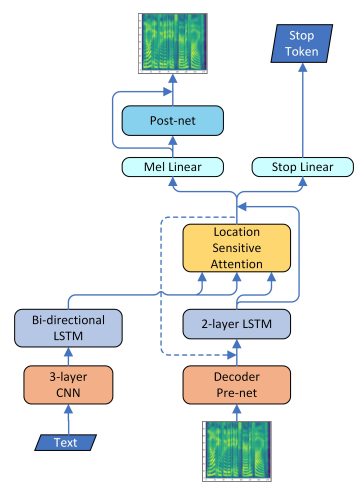
- previous mel-spectrogram frame이 decoder pre-net으로 들어간다.
- decoder pre-net은 2 layer FC이다.
- decoder pre-net의 output은 previous context vecotr와 concat된다.
- Mel Linear은 5 layer CNN이다.
3. Neural TTS with Transformer
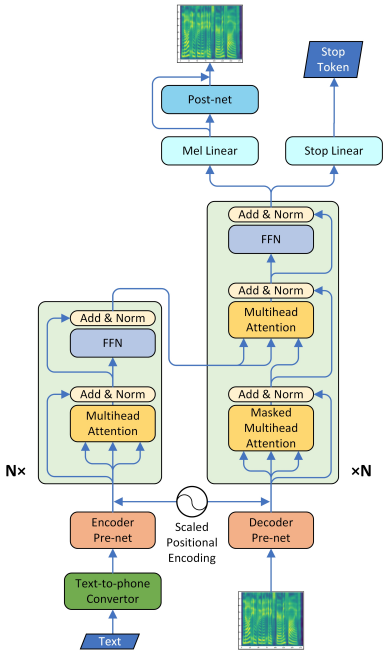
- recurrent connection을 지우므로 parallel training이 가능하게 했다.
- self attention으로 전체 sequence의 global context를 각 input frame에 inject해서 long range dependencies를 만들었다.
3.1 Text-to-Phoneme Converter
- 학습 데이터가 충분하지 않거나 자주 나오지 않는 exception이 있으면 syllable음절의 규칙성을 찾기 어렵다.
- rule system을 만들었다.
3.2 Scaled Positional Encoding
- triangle positional embedding w/ trainable weight를 사용했다.
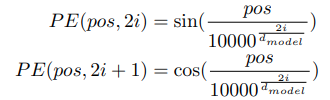
- 아래와 같이 scale을 맞췄다.
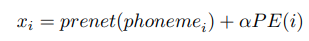
3.3 Encoder Pre-net
- phoneme마다 trainable embedding이 512 dims
- 512 ch의 conv layer + batch norm + ReLU activation + dropout layer + linear projection
- origin에 centered 되지 않으면 mmodel 성능이 떨어지기 때문에 linear projection 사용
3.4 Decoder Pre-net
- 2 FC layer + Relu
- mel spectrogram을 phoneme embedding과 같은 subspace가 되도록 projecting함.
- hidden size를 256로, final position embedding이 encoder라 다르기 때문에 linear projection을 이용하여 origin centered도 하고, 차원도 맞춤
3.5 Encoder
- multi-head attention
- 하나의 attention을 여러개의 subspace로 나눔.(?) 따라서 frame relationship을 여러 다른 측면으로 모델링함.
- long-time depedency를 바로 build
- 병렬 컴퓨팅으로 training speed 향상
3.6 Decoder
- location-sensitive attention 대신에 multi-head attention을 사용했다.
- location-sensitive로 multi-head attention을 바꾸려고 했지만, 이것은 학습 시간과 메모리 문제가 생김
3.8 Mel Linear, Stop Linear, Post-net
- 5-layer CNN으로 mel spectrogram과 stop token을 예측
- 시퀀스마다 stop은 1번 +로 나온다. 대부분은 시퀀스의 마지막이 아니기 때문에 -로 나온다. inbalance를 해소하기 위해 binary cross entropy loss를 구할 때 positive weight를 부과해서 이를 해소했다.
4. Experience
4.1 Training Setup
- 시퀀스의 길이가 다르기 때문에 batch size를 고정하기 어려웠다.
- batch size는 유동적으로, mel spectrogram의 최대 개수는 fixed해서 train했다.
- multi-GPU 학습으로 학습이 잘 안되던 문제를 해결했다.
4.2 Text-to-Phoneme Conversion and preprocess
- Tacotrons은 character sequence를 input으로 학습했는데, transformer-TTS에서는 prenormalized phoneme sequence로 학습했다.
- phoneme sequence로 만들기 위해 sentence separation, text normalization, word segmentation 을 통해 최종적으로 발음을 얻었다.
- Text-to-Phoneme Conversion는 mispronounceation 문제를 크게 줄였다.
4.3 WaveNet settings
- vocoder로 사용한 Wavenet은 sample rate를 16000, gt mel spectrogram의 frame rate를 80으로 사용하였다.
- 2 QRNN layer + 20 dilated layer + residual channels과 dilation channels의 개수는 256개
-
QRNN의 final output은 200 번 copy, 오디오 샘플과 같은 공간적 해상도를 갖고 20 dilated layer 조건이 되기 위해
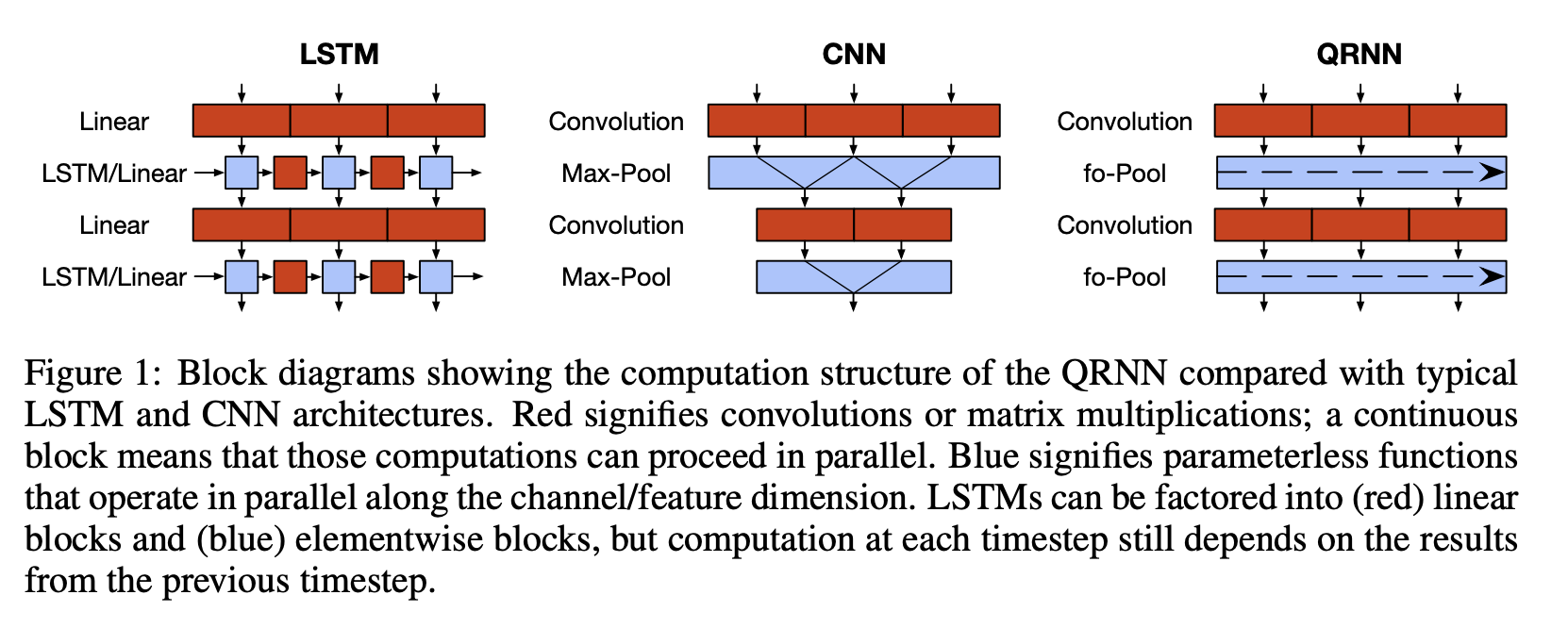
QRNN
- convolution layer를 사용하여 LSTM보다 16배 빠르다.
- masked conv 사용해서 future info 사용 x
4.4 Training time comparison
training time 이 빨랐다. 하지만 converge하는데 3일 걸렸다.
4.5 Evaluation
- Mean option score(MOS)
- 38 fixed example
- 20명의 영어 원어민이 평가
- Comparison mean option score(CMOS)
- tacotron2와 transformer-TTS가 만든 2 audio를 듣고 둘을 비교
- Mel spectrogram을 비교
- GT와 비교해보니 tansformer-TTS가 잘 만듦.
4.6 Ablation studies
- center-consistence를 만들어 주는 linear projection을 제거하니 성능 떨어짐
- position embedding시 trainable scare을 사용하여 embedding space에 더 adaptive한 모델을 만들었는데, absolute position embedding을 사용하니 시퀀스가 길때 음소가 missing되는 문제가 나왔다.
- layer를 추가할 수록 소리가 더 자연스럽고, mel spectrogram 구현도 잘 했다.
- head가 적을 수록 학습 시간을 줄었지만, 성능은 떨어졌다.
5. Related work
- 전통적인 음성 합성
- concatenative system : wave -> small unit -> 새로운 wave 합성
- parametric system : wave -> spectrogram, acoustic parameter
- 도메인 지식이 요구 됨, brittle하게 설계
- 최근 음성 합성
- Tacotron은 end-to-end text-to-speech model, <text, spectrogram>으로 학습
- WaveNet은 waveform synthesis, dilated convolutional layer를 쌓아서, raw audio를 아주 높은 해상도로 처리
- Paralle WaveNet : 추론시간 줄임
- ClariNet : fully convolutional text-to-wave neural architecture
- VoiceLoop : neural TTS + sample based로 합성
- Neural machine translation
- RNN-based, CNN-based : 떨어진 것들의 dependencies를 학습하기 어려웠다.
- transformer의 self-attention이 위 문제를 해소
- SAGAN에서 transformer로 특정 class에 있는 몇몇 geometric하거나 structural pattern을 학습할 수 있었다.
- multi-head attention은 multi-subspace간의 different relation을 얻을 수 있다.
6. Conclusion and Future work
- Tacotron2와 Transformer를 기반으로 병렬로 학습하고, long-distance dependency를 학습하여 학습도 빠르게 하고, 소리도 부드러워 졌다.
- batch size가 중요하다.
- layer를 늘릴 수록 mel-spectrogram을 특히 고주파에 대하여 더 잘 합성하고, 모델 성능이 좋아진다.
- autoregressive model의 문제를 해결하진 못함
- slow inference : dependency of previous frames
- exploration bias : error 축적
- future work로 non-autoregressive model을 하겠다.