Meta-transfer learning for zero-shot super-resolution
본 포스팅은 아래 논문과 동영상을 정리한 것입니다.
- https://arxiv.org/pdf/2002.12213.pdf
- https://www.youtube.com/watch?v=PUtFz4vqXHQ&ab_channel=%EB%8F%99%EB%B9%88%EB%82%98
Abstract
- single image super-resolution(SISR) -> supervised
- large-scale의 external sample을 이용
- internal infomation을 이용하지 못하는 단점
- 학습 데이터에 의존
- 보통 LR image를 bicubic downsampling으로 만드는데, 이렇게 bicubic 한(?) 이미지가 아니면 super-resolution 하기 어렵다.
- zero-shot super-resolution(ZSSR) -> unsupervised
- flexible한 internal learning 방식
- 아주 많은 gradient update가 필요, 긴 inference time
- 이 논문은 ZSSR을 활용해 meta-transfer learning for zero-shot super-resolution(MZSR)
- internal learning에 적합한 initial parameter를 찾는 것
- external info와 internal info를 둘 다 이용하고 적은 gradient update를 한다.
- fast adaptation
1. Introduction
- SISR
- LR 이미지로 부터 그럴 듯한 HR 이미지를 얻는다.
- CNN-based한 방식이 많다. 예시로 VDSR과 같은 것이 있다.
- 보통 bicubic downsampling과 같은 degradation model을 사용한다.
- Sota는 PSNR이 높았다.
- 하지만 real world에서는 다양한 down-sampling과 noise가 있다.
- domain-gap 때문에 안좋은 성능이 나타나기도 했다.
- non-local self-similarity, internal recurrence를 이용하는 방법
- internal distribution을 학습하는 방식. 예시로 zero-shot super-resolution이 있다.
- recurrence가 뚜렷할 때 zero-shot이 도움이 된다.
- 몇가지 limitation이 있다.
- test time에 gradient update를 많이 해야 한다.
- large-scale의 external dataset을 이용하지 못한다.
- 결국 external-based 방식보다 성능이 좋지 않았다.
- meta-learning, Model-Agnostic Meta-Learning(MAML)
- 초기 가중치(base-learner)를 찾는 방법
- 적은 gradient step으로 새로운 task에 빠르게 적응할 수 있다.
- ZSSR과 meta-learning을 활용해 Meta-transfer learning for zero-shot super-resolution(MZSR)을 제안한다.
- kernel agnostic하다.
- tranfer learning
- external sample을 활용할 수 있다.
- bicubic degradation setting으로 데이터를 합성했다.
- meta-learning
- 다른 downsampling kernel을 다른 task처럼 생각해서 학습
- meta-test
- self-supervised learning을 few gradient step으로 할 수 있다.
- lightweight network, 여러 degradation condition에 대해서 flexible
summary
- meta-transfer learning : zero-shot unsupervised setting과 함께 fast adaptation을 위한 initial weight
- external, internal info를 사용해서 좋음
- meta-test time에 fast, flexible, lightweight, unsupervised
2. Related work
2.1 CNN-based super-resolution
2.1.1 SISR
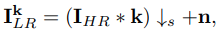
- blur kernel(k)
- scale factor s로 decimation
- gaussian noise
- bicubic downsampling 시나리오에서는 잘 되지만, non-bicubic case에서는 domain gap때문에 성능이 떨어진다.
2.1.2 SRMD
- multiple degradation kernel에 대처
- non-bicubic 상황에서 SISR 방법보다 낫다.
2.1.3 IKC
- blind super-resolution
2.1.4 ZSSR
- image의 internal structure를 학습하도록 제안됨.
- flexibility때문에 real-world에 적용할 수 있다.
2.2 Meta-Learning
- metric based methods
- memory network-based methods
- optimization based methods
- MAML
- 이 논문에서 MAML을 zero-shot super-resolution의 fast adaptation,을 위해 사용됨.
3. Preliminary
3.1 Zero-shot super-resolution
- ZSSR은 unsupervised거나 self-supervised이다. train과 test가 동시에 진행
- $I_{LR}$을 downsample해서 $I_{son}$를 만들어서 학습하면 input image로 super-resolved image를 얻을 수 있다.
3.2 Meta-learning
- meta-training + meta-test
- different task에 빠르게 adapt 할 수 있게 base-learner를 학습
(initial transferable point를 학습) - MAML을 사용
- 다양한 blur kernel들을 다른 task라고 하고 학습
- different task에 빠르게 adapt 할 수 있게 base-learner를 학습
4. Method
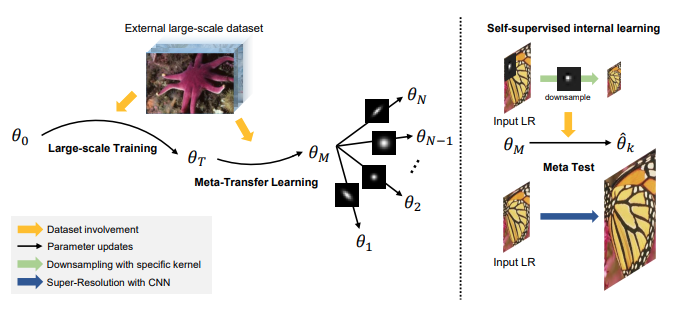
4.1 Large-scale Training
- DIV2K라는 high-quality dataset을 이용하였다. bicubic degradation을 이용하여 $I_{LR}$을 만들어서 학습에 사용했다.
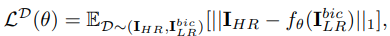
- super-resolution 분야에서는 $l_1$ loss가 많이 쓰인다.
- super-resolution tasks는 비슷한 성질을 공유한다.
- MAML는 unstable training이라고 알려져있다. (pre-train으로 보완)
4.2 Meta-Transfer Learning
- MAML에서와 다른 점
- meta-train(external dataset)과 meta-test(internal learning)에 다른 setting을 적용했다. kernel-agnostic을 위해
- 다양한 kernel
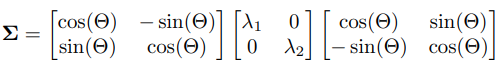 ]
]
- parameter update
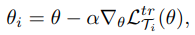
- Ti에 대한 error로 parameter를 update하고
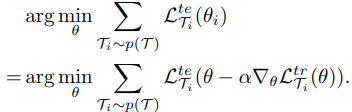
- 모든 task의 loss의 합을 최소화하는 $\theta$를 찾아야하므로
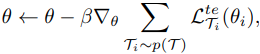
- 위와 같이 gradient descent를 한다.
4.3 Meta-test
- $I_{LR}$을 downsample해서 $I_{son}$을 생성해서 둘을 이용하여 few gradient update를 하고
- $I_{LR}$를 입력하여 super-resolved image를 얻는다.
4.4 Algorithm

- 위 pseudo code에서는 large-scale training과 meta-learning을 한다.

5. Experiments
5.1 Training details
- ZSSR : 8-layer CNN, 255K
- $\alpha = 0.01, \beta = 0.0001$
- 5 gradient updates
- $64\times 64$의 training patch
- gradient vanish와 explode 문제를 해결하기 위해 weighted sum of loss from each step 을 사용
- Adam optimizer를 사용
- subsampling process를 할 때는 direct와 bicubic subsamping method를 위한 모델을 각각 학습했다.
5.2 Evaluations on “Bicubic” Downsampling
- benchmark : Set5, BSD100, Urban100
- measure : PSNR, SSIM
- compare : CARN, RCAN (bicubic downsampling condition)
- compare : ZSSR
- ZSSR과 MZSR(이 논문)은 nonbicubic interpolation에 강했다.
- ZSSR은 많은 update를 해야했다.

- PSNR/SSIM으로 평가
- 괄호( )는 update 횟수
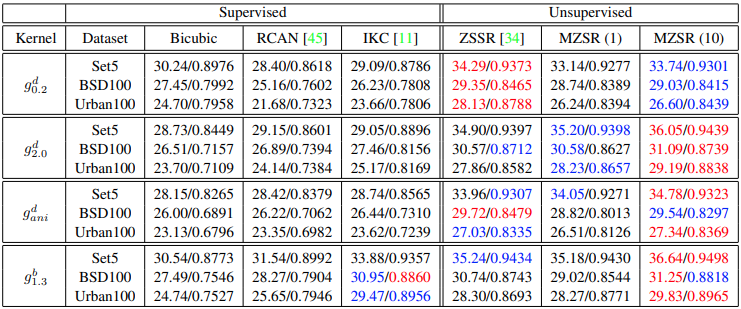
- 다양한 kernel로 test했을 때는 역시 zero shot 기반의 unsupervised에서 잘 되었다.
6. Discussion
- gradient update를 적게 했다.
- multi-scale models : 2배/4배
- low complexity
7. Conclusion
- fast, flexible, lightweight self-supervised super-resolution method
- internal, external infomation
- optimization-based meta-learning + 여러 blur kernel에 sensitive한 transfer learning
- 성능 좋았다.