NLP - Text preprocessing
본 포스팅은 아래 위키독을 참고하여 작성되었습니다.
https://wikidocs.net/book/2155
Text preprocessing
1. 토큰화(Tokenization)
문장은 토큰화, 정제, 정규화 과정을 거쳐야함
-
토크나이저에 따라 결과가 다름
-
토큰화에서 고려해야 할 사항
- 구두점이나 특수 문자를 단순 제외해서는 안된다.
- 줄임말과 단어 내의 띄어쓰기
- 토큰화 도구 NLTK word_tokenize와 WordPunctTokenizer
- 문장 토큰화도 할 수 있음 (NLTK의 sent_tokenize)
한국어
- 교착어 : 자립 형태소, 의존 형태소
- 품사 태깅 : PRP는 인칭 대명사, VBP는 동사, RB는 부사, VBG는 현재부사, IN은 전치사, NNP는 고유 명사, NNS는 복수형 명사, CC는 접속사, DT는 관사
2. 정제(Cleaning) and 정규화(Normalization)
- 정제(cleaning) : 갖고 있는 코퍼스로부터 노이즈 데이터를 제거한다.
- 정규화(normalization) : 표현 방법이 다른 단어들을 통합시켜서 같은 단어로 만들어준다.
- 대, 소문자 통합
- 불필요한 단어의 제거
- 등장 빈도가 적은 단어
- 길이가 짧은 단어(한국어에서는 안된다.)
3. 어간 추출(Stemming) and 표제어 추출(Lemmatization)
- 하나의 단어로 일반화시켜서 문서 내의 단어 수를 줄인다.
- 표제어 추출(Lemmatization)
- 일반화된 단어로 변경
- NLTK WordNetLemmatizer
- 어간 추출(stemming)
- 중요한 단어 추출
- PorterStemmer
- 한국어
- 체언 : 명사, 대명사, 수사
- 수식언 : 관형사, 부사
- 관계언 : 조사
- 독립언 : 감탄사
- 용언 : 동사, 형용사
4. 불용어
- 큰 의미가 없는 단어 토큰을 제거하는 작업
5. 정규표현식
6. 정수 인코딩
단어를 빈도수가 높은 순서대로 낮은 숫자를 부여
- Counter
- NLTK의 FreqDist
7. 패딩
# tensorflow에서
padded = pad_sequences(encoded, padding='post', truncating='post', value=last_value, maxlen=5)
8. 원-핫 인코딩
단어간의 유사성을 계산할 수 없다.
단어의 잠재 의미를 반영하여 다차원 공간에 벡터화
- 카운트 기반 : LSA(잠재 의미 분석), HAL
- 예측 기반 : NNLM, RNNLM, Word2Vec, FastText
- 카운트 기반, 예측 기반 : GloVe
9. 데이터 분리
# zip 이용
X, y = zip(['a', 1], ['b', 2], ['c', 3])
# dataframe 이용
df = pd.DataFrame(values, columns=columns)
# numpy 이용
np_array = np.arange(0,16).reshape((4,4))
X = np_array[:, :3]
y = np_array[:,3]
10. 한국어 전처리 패키지
- PyKoSpacing
- 띄어쓰기가 되어있지 않은 문장을 띄어쓰기 해줌(spacing)
- Py-Hanspell
- 네이버 한글 맞춤법
from hanspell import spell_checker
sent = "맞춤법 틀리면 외 않되? 쓰고싶은대로쓰면돼지 "
spelled_sent = spell_checker.check(sent)
hanspell_sent = spelled_sent.checked
print(hanspell_sent)
- SOYNLP를 이용한 단어 토큰화
- soynlp는 품사 태깅, 단어 토큰화 등을 지원하는 단어 토크나이저
- 비지도 학습으로 단어를 토큰화
- soynlp 단어 토크나이저는 내부적으로 단어 점수 표로 동작합니다. 이 점수는 응집 확률(cohesion probability)과 브랜칭 엔트로피(branching entropy)를 활용
- 응집확률 : 문자열을 문자 단위로 분리하여 내부 문자열을 만드는 과정에서 왼쪽부터 순서대로 문자를 추가하면서 각 문자열이 주어졌을 때 그 다음 문자가 나올 확률을 계산하여 누적곱
- 브랜칭 엔트로피 : 주어진 문자열에서 얼마나 다음 문자가 등장할 수 있는지를 판단하는 척도
- 응집확률 : 문자열을 문자 단위로 분리하여 내부 문자열을 만드는 과정에서 왼쪽부터 순서대로 문자를 추가하면서 각 문자열이 주어졌을 때 그 다음 문자가 나올 확률을 계산하여 누적곱
- 분리 기준을 점수가 가장 높은 L 토큰을 찾아내는 원리
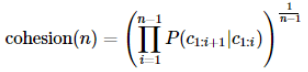
word_extractor = WordExtractor()
word_extractor.train(corpus)
word_score_table = word_extractor.extract()
- 반복되는 문자 정제
from soynlp.normalizer import *
print(emoticon_normalize('앜ㅋㅋㅋㅋ이영화존잼쓰ㅠㅠㅠㅠㅠ', num_repeats=2))
print(emoticon_normalize('앜ㅋㅋㅋㅋㅋㅋㅋㅋㅋ이영화존잼쓰ㅠㅠㅠㅠ', num_repeats=2))
print(emoticon_normalize('앜ㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋ이영화존잼쓰ㅠㅠㅠㅠㅠㅠ', num_repeats=2))
print(emoticon_normalize('앜ㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋ이영화존잼쓰ㅠㅠㅠㅠㅠㅠㅠㅠ', num_repeats=2))
- Customized KoNLPy
from ckonlpy.tag import Twitter
twitter = Twitter()
twitter.add_dictionary('은경이', 'Noun')
twitter.morphs('은경이는 사무실로 갔습니다.')