NLP - Language Model
본 포스팅은 아래 위키독을 참고하여 작성되었습니다.
https://wikidocs.net/book/2155
Language Model
1. 언어 모델
앞으로나올 단어 예측
2. 통계적 언어모델
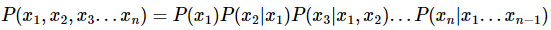
- 희소 문제(sparsity problem) : 학습데이터에 없는 것
3. N-gram 언어모델
n개의 연속적인 단어 나열을 의미
- 희소 문제(Sparsity Problem)
- n을 선택하는 것은 trade-off 문제
- 희소의 문제(작으면 좋음)와 정확도의 문제(크면 좋음)
- 5를 넘지 않길 권장
- 언어 모델의 약점 : 훈련에 사용된 도메인 코퍼스가 무엇이냐에 따라서 성능이 비약적으로 달라지기 때문입니다.
4. 한국어에서의 언어 모델
- 한국어는 어순이 중요하지 않다.
- 한국어는 교착어이다.
- 한국어는 띄어쓰기가 제대로 지켜지지 않는다.
5. 펄플렉서티(Perplexity, PPL)
- 헷갈리는 정도
- ‘낮을수록’ 언어 모델의 성능이 좋다.
- 문장의 길이로 정규화된 문장 확률의 역수
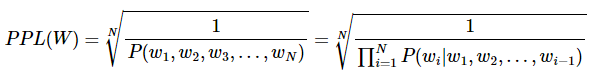
- 분기 계수(branching factor)
- PPL은 선택할 수 있는 가능한 경우의 수를 의미하는 분기계수(branching factor)
- PPL은 이 언어 모델이 특정 시점에서 평균적으로 몇 개의 선택지를 가지고 고민하고 있는지를 의미합니다.
- 테스트 데이터 상에서 높은 정확도를 보인다는 것이지, 사람이 직접 느끼기에 좋은 언어 모델이라는 것을 반드시 의미하진 않는다는 점입니다.