본 포스팅은 아래 논문을 참고했습니다. https://arxiv.org/pdf/2010.11929.pdf
1. Introduction
자연어 처리에서 많이 쓰게 된 transformer를 이미지에도 적용해본 논문.
자연어 처리에서는 주로 큰 text corpus를 pre-train하고, 더 작은 task에 맞춰서 fine-tuning 했다. Transformer의 computational effciency와 scalability에서의 장점으로 아주 큰 데이터를 학습할 수 있게 됐다.
vision에서도 transformer를 사용하려는 노력이 많았다. 하지만 이론적으로는 효과적이었지만, specialized attention pattern의 사용으로 현대의 하드웨어 가속기에서는 효율적으로 scaled 되지 못했다.
이 논문에서는 vision에도 transformer를 적용하기 위해 image를 patch로 나눴고, linear embedding을 했다. 그리고 patch를 transformer의 word처럼 적용했다.
중간 사이즈의 dataset인 imagenet으로 regularization을 적게 사용해서 학습을 시켰을 때는 성능이 좋지 않았다. 그 이유는 transformer는 부족한 데이터셋으로 학습할 때 inductive biases(예를 들어 equivariance와 locality)가 부족하기 때문이다.
하지만 큰 사이즈의 dataset을 사용할 때는 사이즈가 inductive bias를 이겼고, 좋은 성능을 냈다.
2. Related work
-
이미지에 self-attention을 pixel별로 적용하면, pixel 개수의 제곱의 cost가 들기 때문에 실제 이미지에 적용하기 어렵다. 이런 문제 때문에 인접한 부분만 self-attention 하는 방법도 사용됐는데, 이것은 convolution을 대체할 수 있었다.
-
위에서 알 수 있듯 이미지에도 transformer를 적용할 수 있으려면 메모리 사용을 줄여야 한다. scalable approximation을 사용하는 sparse transformer, attention을 scale하는 방법등을 사용하기도 했다.(?)
-
2x2 patch를 추출해서 이것은 full self-attention에 적용하는 방법도 있었다. 이것은 small-resolution 이미지에만 된다는 한계가 있다.
-
CNN과 self-attention을 결합하는 여러가지 방법들도 나왔다.
-
iGPT : image pixel의 resolution과 color space를 축소해서 transformer에 적용하는 방법
3. Method
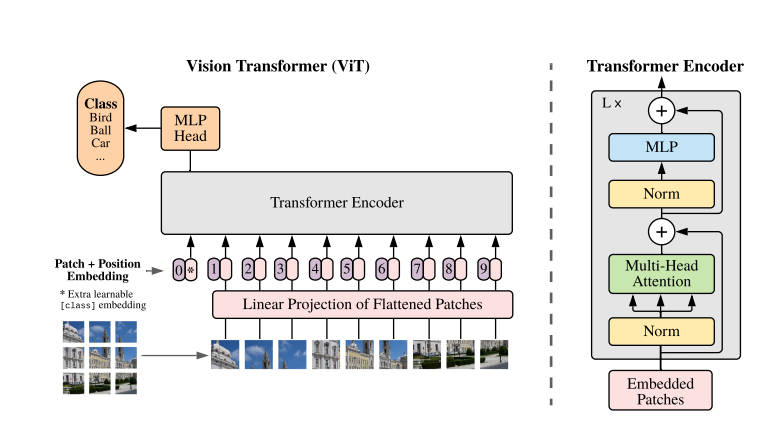
- 최대한 original transformer를 유지하려고 함.
3.1 Vision Transformer
- patch를 PxP 차원을 가지도록 만들어서 $H{\times}W{\times}C$에서 $N{\times}(P^2*C)$로 차원 변경
- embedded patches를 nlp의 token처럼 사용
- 1D position embedding (2D로 한다고 성능이 크게 좋아지지 않음)
- Inductive bias
- Vit가 CNN보다 less image-specific inductive bias 가짐
- CNN : locality, translation equivariance
- Vit : MLP는 locality, translation equivariance 가지지만, self-attention은 global한 성질 가짐
translation invariance
- input의 위치와 상관없이 output이 동일한 값을 갖는것을 말한다.
- CNN은 translation equivariance한 네트워크이다. 하지만 max pooling의 약간의 translation invariance와 softmax의 translation invariance로 인해 translation invariance한 성질도 갖게 된다.
- Max-pooling : 대표적인 small translation invariance, k x k 범위 내에서의 translation에 대해서는 invariance 하다.
- conv layer : object의 위치와 상관없이 특정 패턴을 학습
- softmax
아래 게시물을 참고했습니다.
https://ganghee-lee.tistory.com/43
- Hybrid Architecture : raw image patches 대신 CNN의 feature map이 input으로 들어가기도 함. 이때 1x1 patch가 될 수도 있다.
- Fine-tuning
- high resolution의 이미지로 학습한 후에 FC layer를 붙여서 만듦
- fine-tuning at high resolution을 한 것이 pretraining을 한 것보다 좋기도 하다.
- high resolution으로 학습을 할 때 patch size를 동등하게 하고, seq len을 크게 함. 이렇게 하면, pretrained position embedding의 의미가 없다. 이렇게 되면 2D interpolation