본 포스팅은 아래 게시물을 참고했습니다.
- https://ganghee-lee.tistory.com/35
- https://ganghee-lee.tistory.com/36
- https://herbwood.tistory.com/10
- https://herbwood.tistory.com/20
DETR을 보다가 R-CNN에 대해 궁금해져서 RCNN 에 대해 조사해 보게 되었습니다.
여러가지 중에서도 R-CNN, Fast R-CNN, Faster R-CNN, Mask R-CNN을 알아보겠습니다.
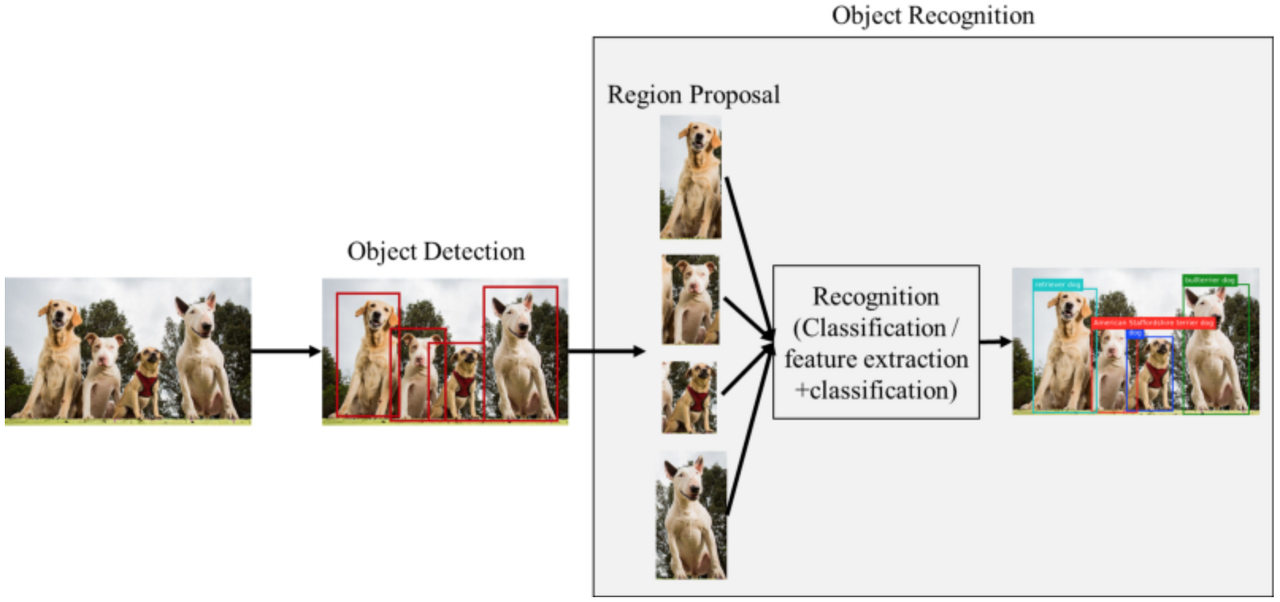
Object Detection
object detection에는 1-stage detector와 2-stage detector가 있다.
2-stage detector
Selective search, Region proposal network 등으로 ROI를 찾고, classification 한다.
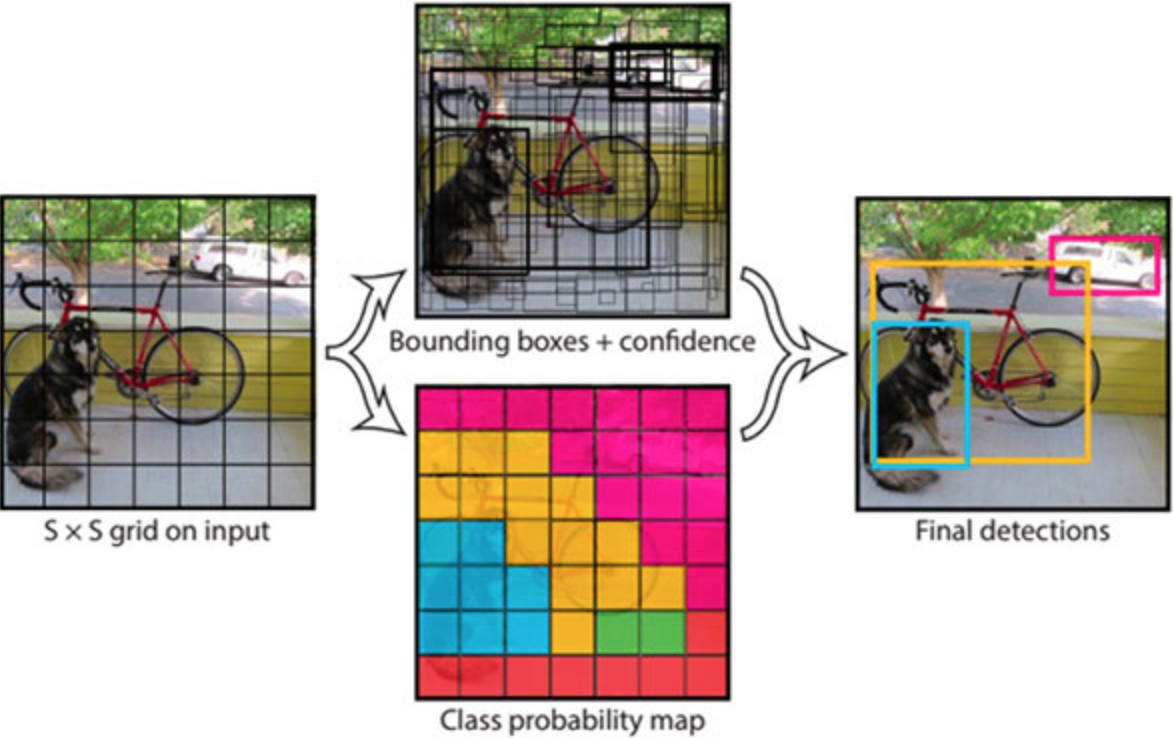
1-stage detector
RoI영역을 먼저 추출하지 않고 전체 image에 대해서 convolution network로 classification, box regression(localization)을 수행한다.
여기서 R-CNN계열은 2-stage Detector이다.
1. R-CNN
- Image classification을 수행하는 CNN + localization을 위한 regional proposal 알고리즘
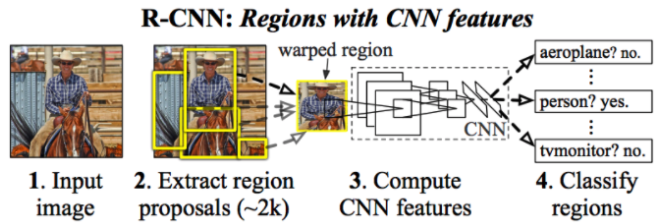
- R-CNN 과정
- Image를 입력받는다.
- Selective search 알고리즘에 의해 regional proposal output 약 2000개를 추출한다. 추출한 regional proposal output을 모두 동일 input size로 만들어주기 위해 warp해준다.
- 2000개의 warped image를 각각 CNN 모델에 넣는다.
- 각각의 Convolution 결과에 대해 (Linear SVM으로) classification을 진행하여 결과를 얻는다.
- Selective search
- 패턴으로 non-object-based segmentation
- Bottom-up 방식으로 small segmented areas들을 합쳐서 더 큰 segmented areas
- 최종적으로 2000개의 region proposal을 생성
-
Bounding box regression Selective search로 만든 bounding box는 정확하지 않기 때문에 물체를 정확히 감싸도록 조정해주는 bounding box regression(선형회귀 모델)이 존재한다.
-
단점
- CNN을 2000번 해야해서 시간이 오래 걸림
- CNN, SVM, Bounding Box Regression 총 세가지의 모델이 한 번에 학습되지 않는다.
2. Fast R-CNN
- fast R-CNN은 다음 두가지를 통해 R-CNN의 단점을 극복했다.
- RoI pooling
- CNN 특징추출, classification, bounding box regression 모두 하나의 모델에서 학습
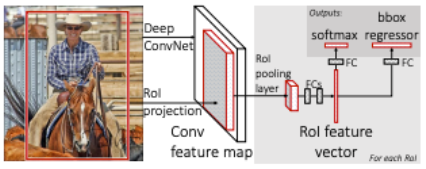
- R-CNN에서와 마찬가지로 Selective Search를 통해 RoI를 찾는다.
- 전체 이미지를 CNN에 통과시켜 feature map을 추출한다.
- Selective Search로 찾았었던 RoI를 feature map크기에 맞춰서 projection시킨다.
- projection시킨 RoI에 대해 RoI Pooling을 진행하여 고정된 크기의 feature vector를 얻는다.
- feature vector는 FC layer를 통과한 뒤, 두 브랜치로 나뉘게 된다.
- 하나는 softmax를 통과하여 RoI에 대해 object classification을 한다.
- bounding box regression을 통해 selective search로 찾은 box의 위치를 조정한다.
- 여기서 FC layer로 들어가기 전에 input을 동일한 size로 맞춰야 한다.
- RoI를 crop, warp을 통해 동일 size로 조정
RoI Pooling
- CNN을 2천번 하던 것이 1번으로 줄었다.
- Fast R-CNN에서 먼저 입력 이미지를 CNN에 통과시켜 feature map을 추출
- Selective search로 roi를 찾고, 이것을 feature map에 projection
- ROI를 FC layer input 크기에 맞게 고정된 크기로 변형
-
SPP를 참고하였다.
Spatial Pyramid Pooling(SPP)
1. CNN으로 feature map을 추출 2. 4x4, 2x2, 1x1로 feature map을 나누고, max pooling 한다. 3. max값들을 쭉 이어붙여 고정된 크기 vector를 만든다. CNN을 통과한 feature map에서 2천개의 region proposal을 만들고 region proposal마다 SPPNet에 집어넣어 고정된 크기의 feature vector를 만들었다.
End-to-end로 학습 (아직 이해 안됨)
동일 data가 각자 softmax(classification), bbox regressor(localization)으로 들어가기에 연산을 공유한다.
이는 이제 모델이 end-to-end로 한 번에 학습시킬 수 있다는 뜻이다.
결론
RoI pooling으로 CNN 연산 줄이고, end-to-end 학습 가능해졌다.
여전히 남은 단점은 selective search 알고리즘으로 생기는 bottleneck이었다.
3. Faster R-CNN
- RPN + Fast R-CNN
- Region Proposal Network : 후보 영역 추출 작업
- Anchor box : 가로세로비를 가지는 bounding box
- end-to-end로 네트워크를 학습시키는 것이 가능
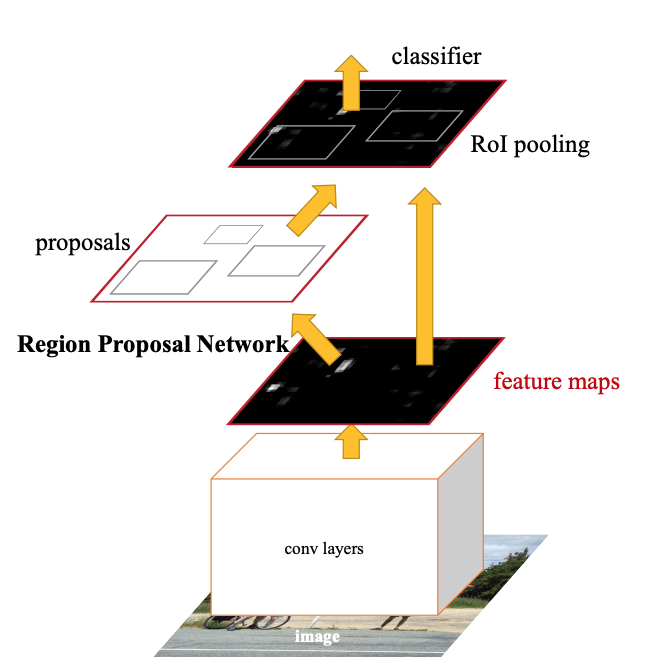
- 원본 이미지를 pre-trained된 CNN 모델에 입력하여 feature map을 얻습니다.
- feature map은 RPN에 전달되어 적절한 region proposals을 산출합니다.
- region proposals와 1) 과정에서 얻은 feature map을 통해 RoI pooling을 수행하여 고정된 크기의 feature map을 얻습니다.
- Fast R-CNN 모델에 고정된 크기의 feature map을 입력하여 Classification과 Bounding box regression을 수행합니다.
Anchor box
- 이와 비슷한 Dense sampling : grid를 bounding box로 간주하는 방법, feature map의 크기는 (H x sub-sampling ratio) x (W x sub-sampling ratio)
- 3가지 scale과 3가지 aspect ratio를 가지는 총 9개의 서로 다른 anchor box를 grid cell의 중심을 기준으로 생성
RPN(Region Proposal Network)
- RPN은 region proposals에 대하여 class score를 매기고, bounding box coefficient를 출력하는 기능
- 결국 cnn을 하는 것
- 원본 이미지를 pre-trained된 VGG 모델에 입력하여 feature map을 얻습니다. (원본 이미지의 크기가 800x800, sub-sampling ratio가 1/100, 8x8 크기의 feature map, 512개의 channel)
- feature map에 대하여 3x3 conv 연산을 적용합니다. 이때 feature map의 크기가 유지될 수 있도록 padding을 추가합니다. (8x8x512개의 feature map -> 8x8x512개의 feature map)
- 1x1 conv 연산, feature map의 channel 수가 2(object의 여부)x9(anchor box 9개)
- bounding box regressor를 얻기 위해 feature map에 대하여 1x1 conv 연산을 적용합니다. 이 때 출력하는 feature map의 channel 수가 4(bounding box regressor)x9(anchor box 9개)
Multi-task loss
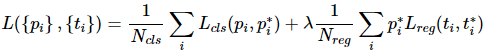

Train
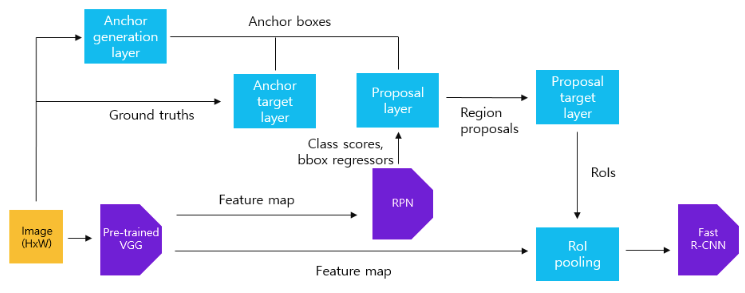
- Alternating Training : 번갈아가며 학습
Inferencezzz
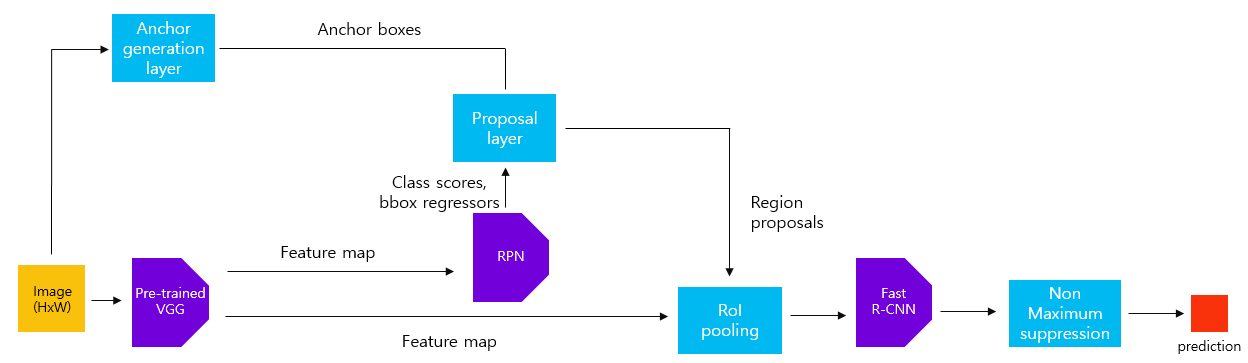
4. Mask R-CNN
- instance segmentation task
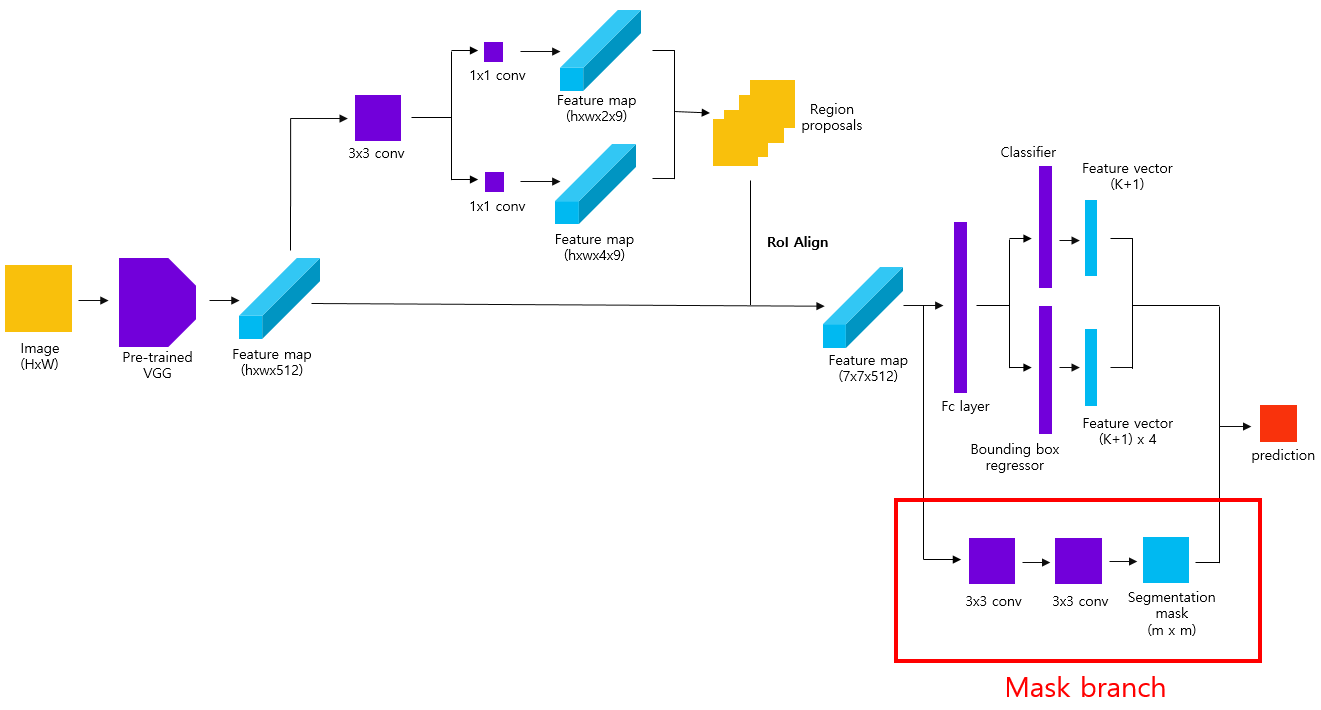
- ROIAlign
- RoI pooling으로 인해 얻은 feature와 RoI 사이가 어긋나는 misalignment
- pixel mask를 예측하는데 매우 안 좋은 영향
- RPN을 통해 얻은 RoI를 backbone network에서 추출한 feature map의 크기에 맞게 투영(projection)
- RoI projection을 통해 얻은 feature map -> 3x3 크기의 feature map
- 4개의 sampling point
- Bilinear interpolation
- $L = L_{cls}+L_{box}+L_{mask}$