Shadow attach
본 포스팅은 아래 게시물을 참고했습니다.
- https://arxiv.org/pdf/2003.08937.pdf
- https://www.youtube.com/watch?v=D1j3QiXPRag&ab_channel=%EB%8F%99%EB%B9%88%EB%82%98
유튜브에 있는 논문 리뷰를 보는데, 익숙하지 않은 개념인 adversarial attach에 대한 동영상을 보게돼서 정리해봤습니다.
1. Introduction
- 기존의 연구는 cerifiable defense에 초점을 맞춘 연구들이다. 이것은 $l_p$ norm boundary안의 attack을 수학적으로 보장하는 방어 기법인데, 이것은 boundary를 벗어나는 attack에 당연히 취약하다.
- Shadow attach은 $l_p$ norm boundary를 벗어나는 adversarial perturbation으로 attack하는 새로운 adversarial attack 방법
- certified classifier의 attach은 아래와 같은 특징을 가진다.
- Imperceptibility: 정상처럼 보임
- Misclassification : 타겟 클래스로 분류하도록 유도
- Strong certified : 높은 certificate radius를 가짐
- background
- white-box 세팅에서는 1차 gradient 정보로 attack을 많이 했다.예를 들어 Projected Gradient Descent (PGD)가 있고, 이것은 아주 자연스러워서 성능이 좋았다.
- attack을 만들 때 $l_p$ norm 제약을 이용해서 어색하게 지각되는 것을 줄였다.
- semantic adversarial example : HSV 를 바꿔서 attack
- non-certified defense : 실제로 top adversarial defense는 non-certified defense이고, 이것은 adversarial training, 이때 training 하면서 attack image가 나오고, 그 이미지로 다시 학습을 한다.
- Projected Gradient Descent (PGD)
- certified defense : $l_p$-bounded perturbation을 견디도록 학습하는 방법. 예를 들어 $l_2$는 randomized smoothing, $l_{\inf}$는 CROWN-IBP
- 기존의 연구들은 imperceptibility, misclassification에 초점을 두었고, certificates를 manipulate 하는 것을 연구하는 것은 없었다.
2. Shadow attack
기존의 attach의 perturbation은 $\epsilon$ 이내로 제한하여 imperceptibility를 높였다.
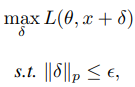
하지만, 이 논문은 아래와 같은 penalties를 사용하였다.
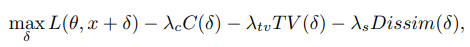
- Penalties : imperceptibility 향상
- $\lambda_cC(\delta)$ : color regularizer, perturbation의 크기에 제한을 둠
- $\lambda_{tv}TV(\delta)$ : smoothing, anisotropic total variance를 줄이게 되면 인접한 픽셀끼리의 값이 유사해지고 노이즈를 제거하고 smoothing하는 효과가 있다. 원래는 adversarial attack을 방어하기 위해 사용되었지만 여기서는 perturbation을 자연스럽게 사용하는 용도로 기존과 다르게 사용되었다.
- $\lambda_{s}Dissim(\delta)$ : perturbation이 비슷한 값을 갖도록 만듦. R,G,B를 비슷하게 해서 grey scale처럼 만듦.
- untargeted attack
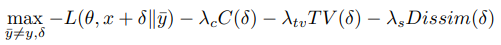
모든 가능한 wrong class $\bar{y}$에 대해서 위 값을 계산하고, 가장 높은 값인 것을 사용했다.
6. Conclusion
- Shadow attack이라는 자연스러운 perturbation을 만드는 attach 방법을 만들었습니다.
- certificates는 수학적으로는 강하지만, robustness나 accuracy에 대한 좋은 indicator는 아닙니다.