kaggle BirdCLEF 2022 - Mel spectrogram
BirdCLEF 2022를 하던 중 음성 데이터에서 feature를 뽑는 방법을 고민해보게 되었다. 그 과정에서 아래 내용을 알게 되었다.
Short Time Fourier Transform
- 음성 데이터를 시간 단위로 나눠서 FFT(주파수 성분 분석과 비슷) 를 하는 것
librosa.stft(y, n_fft=2048, hop_length=None, win_length=None, window='hann', center=True, dtype=None, pad_mode='constant')
- n_fft : 나누는 시간 단위
- hop_length : window간의 거리
- win_length : window의 길이
Mel spectrogram
-
사람은 낮은 주파수를 높은 주파수보다 예민하게 받아들임. 이것을 구현하는 것이 mel scale
-
Mel(f) = 2595 log(1+f/700)
librosa.filters.mel 를 이용하면 mel filter bank를 구할 수 있다.
melspec = librosa.feature.melspectrogram(y=y, sr=params.sr, n_mels=params.n_mels, fmin=params.fmin, fmax=params.fmax,)
melspec = librosa.power_to_db(melspec).astype(np.float32)
- 위와 같이 mel-scaled spectrogram로 바꾼 다음 dB로 magnitude를 바꿔주면 mel spectrogram이 된다.
mel spectrogram 에서 image로
값을 복붙해서 3차원으로 만들고, 정규화를 거친다음, np.clip()으로 0~255 사이의 값으로 만든다.
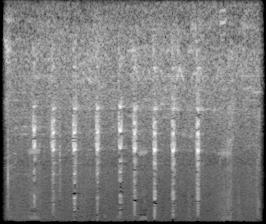
결과
아래 이미지를 보면 알 수 있듯 어떤 공통되는 특징이 있어보이기도 하는데, noise가 너무 많아서 전처리가 필요할 거 같다.
- afrsil1
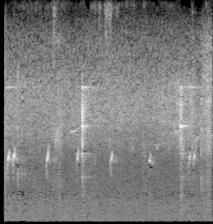
- bknsti
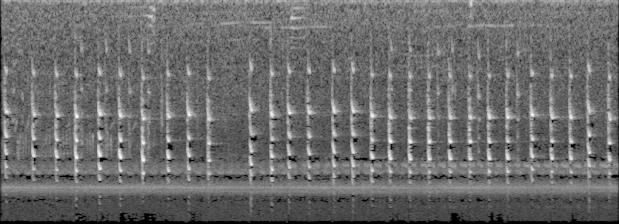
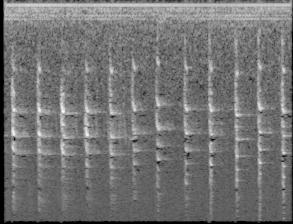
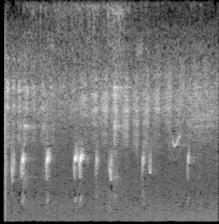
고찰
- 소리를 들어보니 클래스 마다 확실하게 구별되는 feature를 잡을 수 있을 거 같다. 근데 하나의 종이 여러가지 소리를 내기도 하였기 때문에 꼭 학습되어야 하는 데이터가 있는거 같다. cross validation을 사용해야겠다.
- 내가 사용한 방법은 주파수 성분을 추출하는 방법이었는데, 이거 말고도 다른 방법이 있는지 궁금하다.
- 굳이 Mel spectrogram로 바꿔야 하는지 모르겠다. 사실 mel scale로 바꾸면, 고주파 음을 구별하기가 쉽지 않은데, 새 소리는 대부분 고주파 음이다. stft로 변환한 것을 사용해도 될 거 같다.
- 소리를 들어보니 noise가 많고, 소리가 작았다. 일단 noise부터 제거하려고 했는데, 이렇게 전처리를 하기보다 먼저 attention 기법으로 중요한 소리에 집중하도록 학습하고, 그래도 안되면 전처리 쪽을 건들여봐야겠다.
아래 블로그를 참고해서 적었습니다.